New York City’s subway system is run by the Metropolitan Transportation Authority (MTA). On its website, the MTA publishes data sets containing information about entries and exits through the various turnstiles at each of its stations. Each turnstile has a counter for entries and one for exits which continuously count the number of riders passing through.
Using python in a jupyter notebook, I analyzed these data to learn what the busiest stations are, which stations people commute to and from, what times of the day are the busiest, and how the ridership changes on weekends and over the course of a year. Finally, I developed a simple model that predicts the ridership on any given day. The complete jupyter notebook is available on github.
The first thing I looked at was the overall ridership for each station (entries plus exits). The map below shows the busiest subway stops as circular markers whose size corresponds to the passenger volume. Most of them are located in Manhattan, and particularly in Midtown. The busiest station is 34th St/Penn Station. I created the map using matplotlib‘s Basemap.

By looking at the ridership data in the morning and in the evening, I was able to determine which stations people commute from (origins) and which stations they commute to (destinations). If more passengers enter a given station in the morning than in the evening and more passengers exits this station in the evening than in the morning, I can classify it as a commuter origin.
In the following map, blue stations are commuter origins, red stations are commuter destinations. The size of each circle indicates the morning–evening difference in ridership. Clearly, there is a high density of commuter destinations in Manhattan. The commuter origins (blue) are located mostly in the Bronx and the peripheral parts of Queens and Brooklyn.

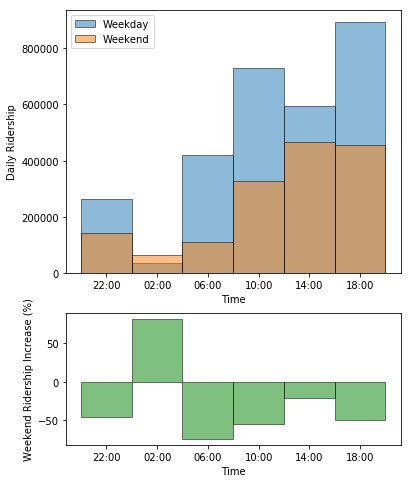
Next, I was interested in the ridership distribution over the course of a day. The histogram below shows the ridership for different parts of the day, distinguishing between weekdays (blue) and weekends (brown). There are generally more riders on weekdays indicating that a large amount of passengers commute to work or school. In addition, the weekend distribution looks different: there are less early-morning trips betwen 4am and 8am, but more late-night trips between midnight and 4am.
The green histogram at the bottom makes this clearer by showing the changes in ridership on the weekend, compared to a weekday.
It’s also interesting to compare the ridership distribution over the course of a day for different stations. For example, the below histogram compares the 183 St. station in the Bronx and the Bedford Avenue station in Williamsburg to the average New York ridership. While passengers in the Bronx use the subway disproportionately in the early morning hours (4-8am) and much less between 4pm and 8pm in the evening, the commute hours in Williamsburg seem to be shifted to later times: there are less trips at the normal commute hours (4-8am and 4-8pm) and more trips between 8am-noon and 8pm-midnight.

Finally, I looked at the total daily ridership over the course of a year. As you can see in the plot below, ridership oscillates due to the decreased number of trips on weekends. Additionally, there is a decrease in weekday ridership between July and September (presumably due to closed schools) and a strong dip around the winter holidays. There are also little spikes where ridership drops sharply to weekend levels in the middle of the week, which are due to major holidays (see for example the dip on July 4th).

I used a linear regression model to predict the daily ridership. The features it is based on are the day of the week, a calendar of school days, a list of national holidays, and key weather metrics such as the average temperature, precipitation and snow depth. Although the model has quantitative deficiencies, it captures the general trends in the data, including the anomalous behavior during the holiday season.
The jupyter notebook of this project is available on GitHub.


You must be logged in to post a comment.