In this project, I used a series of classification algorithms to assign wine to one of three categories based on their chemical composition.
The dataset contains 178 different wines from the same region which belong to three different cultivars. Each of the 178 wines is characterized by 13 numerical features which correspond to different chemical constituents. In order to be able to visualize the data and the classification models, I reduced the dimensionality of the features from 13 to 2 using principal component analysis (PCA) which preserved 56% of the variance information. Below is a visualization of different wines (each wine is one data point) in this reduced two-dimensional feature space.
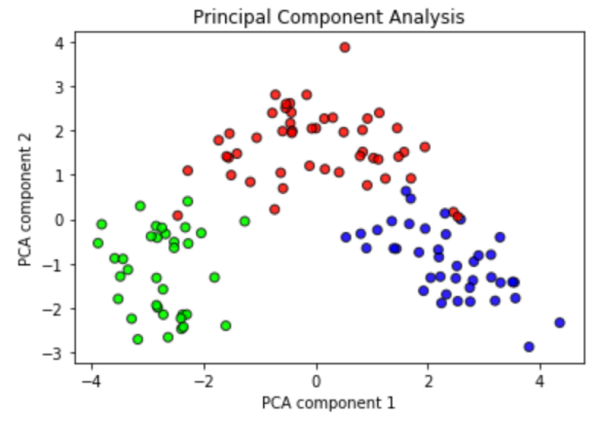
The three different wine cultivars (classes) are represented by three colors. This diagram demonstrates that even after performing PCA, the three classes are well-separated, with only a few samples lying in another classes’ domain.
Next, I trained six different classification algorithms implemented in the scikit-learn module on these data: perceptron, logistic regression, kernel support vector machines (SVM), decision trees, random forests, and k-nearest neighbors (kNN).
Before doing so, however, I split the data so that 70% of the samples (wines) would constitute the training dataset and held back the remaining 30% as the test dataset. The training set is used to build a model describing the data, and the test set is used to verify that the model is capable of predicting the category (class) of unknown data. The two datasets are shown in the two plots below (training set on the left, test set on the right).
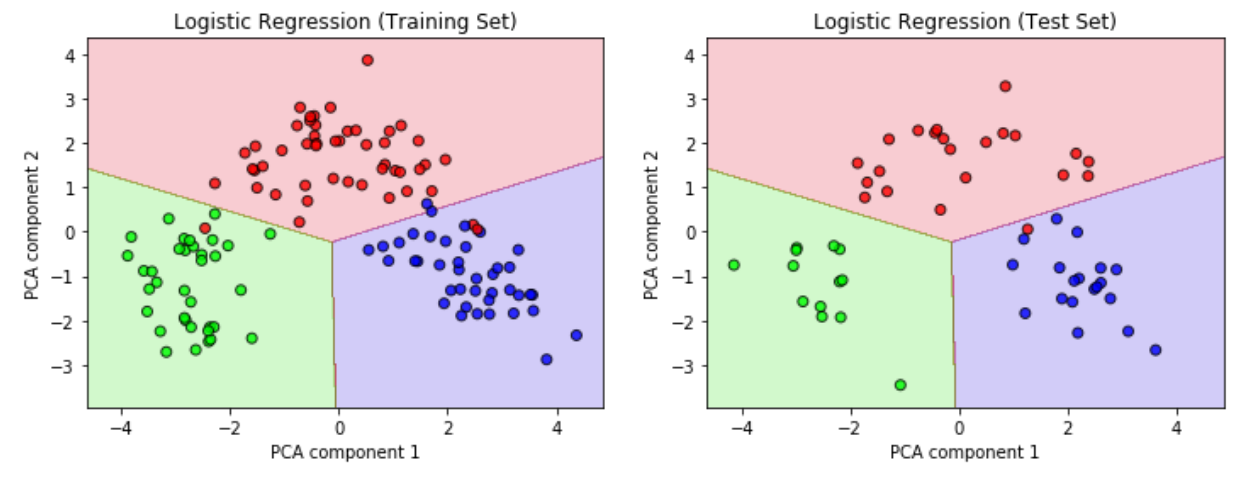
However, the above plots not only show the two datasets (the data points) but also a background of varying color. This background represents the classification model, in this case using the logistic regression algorithm, which was built using only the training set on the left: in areas with a red background, the model predicts that any wine sample lying in this area will belong to the ‘red’ class (as opposed to the other two, the ‘green’ and ‘purple’ wines).
The logistic regression model is then used to predict the class (red vs. green vs. purple) of the test set, which is not ‘known’ to the model and the class labels of which are not fed to the model. Nevertheless it is able to predict the class of the 54 test samples with a great accuracy of 98%.
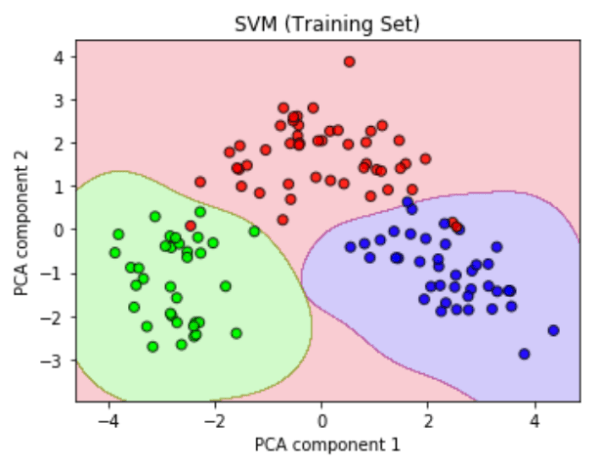
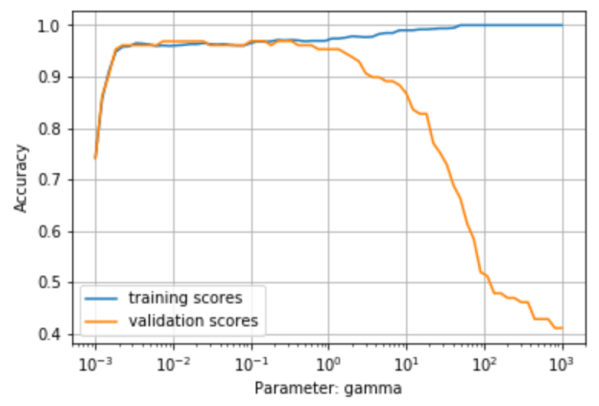
While the logistic regression model partitions the feature space by linear boundaries, there are also non-linear models such as the kernel support vector machines (SVM) algorithm. The left plot below shows the same training set as before but it is now overlaid with the predictions of the SVM model. The exact shape of the green and purple domains is determined largely by a hyperparameter named gamma. I used the validation curve shown on the right to determine the optimal value for gamma, which is the value at which the accuracy of the validation score (orange) is maximized.
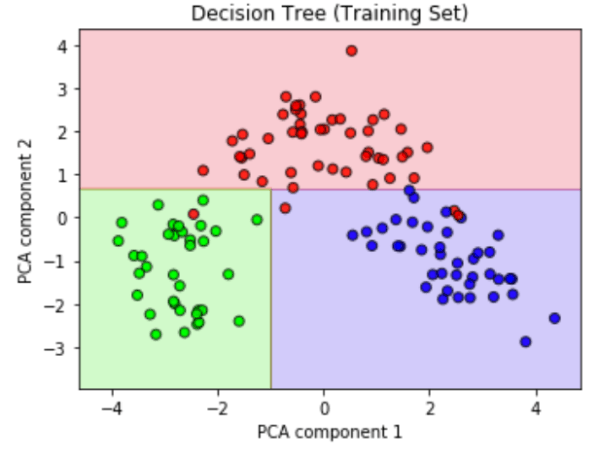
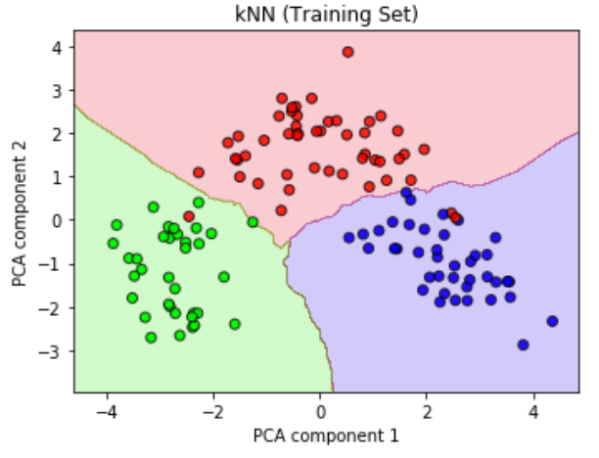
In a similar fashion, I also trained the remaining models on the data. The two following diagrams show the training data with a decision tree model (left) and a k-nearest neighbor model (kNN, right). I evaluated each algorithm through the accuracy of it’s class predictions for the test set and the their respective time required to be trained. As it turns out, the k-nearest neighbors model performed best on this dataset.
The python code of this project is available in a jupyter notebook on GitHub.







 Determining the properties of a new material through experimentation and rigorous theoretical calculations is time-consuming and costly. This is particularly challenging when a large number of candidate materials needs to be assessed regarding their suitability for a specific application. However, by using machine learning, material properties can be inferred in a more efficient manner. The results can be used to quickly select a smaller subset of the candidate materials which can then be investigated with experiments and calculations.
Determining the properties of a new material through experimentation and rigorous theoretical calculations is time-consuming and costly. This is particularly challenging when a large number of candidate materials needs to be assessed regarding their suitability for a specific application. However, by using machine learning, material properties can be inferred in a more efficient manner. The results can be used to quickly select a smaller subset of the candidate materials which can then be investigated with experiments and calculations. We then used linear regression and random forest regression to predict key physical properties. While linear regression strongly overfit the data, random forest regression gave a more accurate prediction.
We then used linear regression and random forest regression to predict key physical properties. While linear regression strongly overfit the data, random forest regression gave a more accurate prediction.
You must be logged in to post a comment.